The hangover
Every time you call an LLM, it wakes up with no memory of last night. The request is stateless. It doesn’t remember what it did last session, it doesn’t know it made this exact mistake yesterday, and it definitely can’t tell you whether it’s getting more reliable or less. You wire up an agent, it does something dumb, you fix the prompt, and three days later it does the same dumb thing in a slightly different outfit.
We kept coming back to one idea. The problem isn’t that agents fail. Agents will always fail sometimes. The problem is that they fail the same way forever, because nothing remembers the last time. So we built Mnemo, a memory for AI agents that learns from their failures, on top of Cognee, the hackathon’s memory layer. The code is open source: Mnemo on GitHub.
The one line we kept on the wall: the memory is the product. Strip Cognee out of Mnemo and there’s nothing left but a stateless judge anyone could write in an afternoon. The whole point is cross-run learning.
What Mnemo actually does
A small real agent (DeepSeek doing function-calling over a set of tools) runs support tasks. Refund this invoice, reset that password, close this account. Its runs get remembered into a Cognee knowledge graph: the task, the tools it called, the outcome. Then, before we judge a new run, we recall similar past runs and hand them to an LLM judge as evidence. When a human corrects a verdict, we feed the correction back so the graph improves. And when data goes stale or private, we forget it.
That maps onto Cognee’s four lifecycle APIs, which is what made it fun to build.
remember()turns each run into a structured document in the graph, tagged per agent, so the graph learns the shape of “invoice-bot keeps misreading decimals” and “support-bot keeps skipping identity checks.”recall()runs before we judge. We ask the graph whether we’ve seen this failure before. Cognee routes between semantic similarity and graph traversal, and the hits become citations in the verdict.improve()is the learning step. A human overrides a verdict, the correction gets remembered as authoritative policy, and the next similar run recalls it and the judge changes its mind. No code change. The system learned.forget()prunes a dataset. The graph shrinks and recall stops surfacing it.
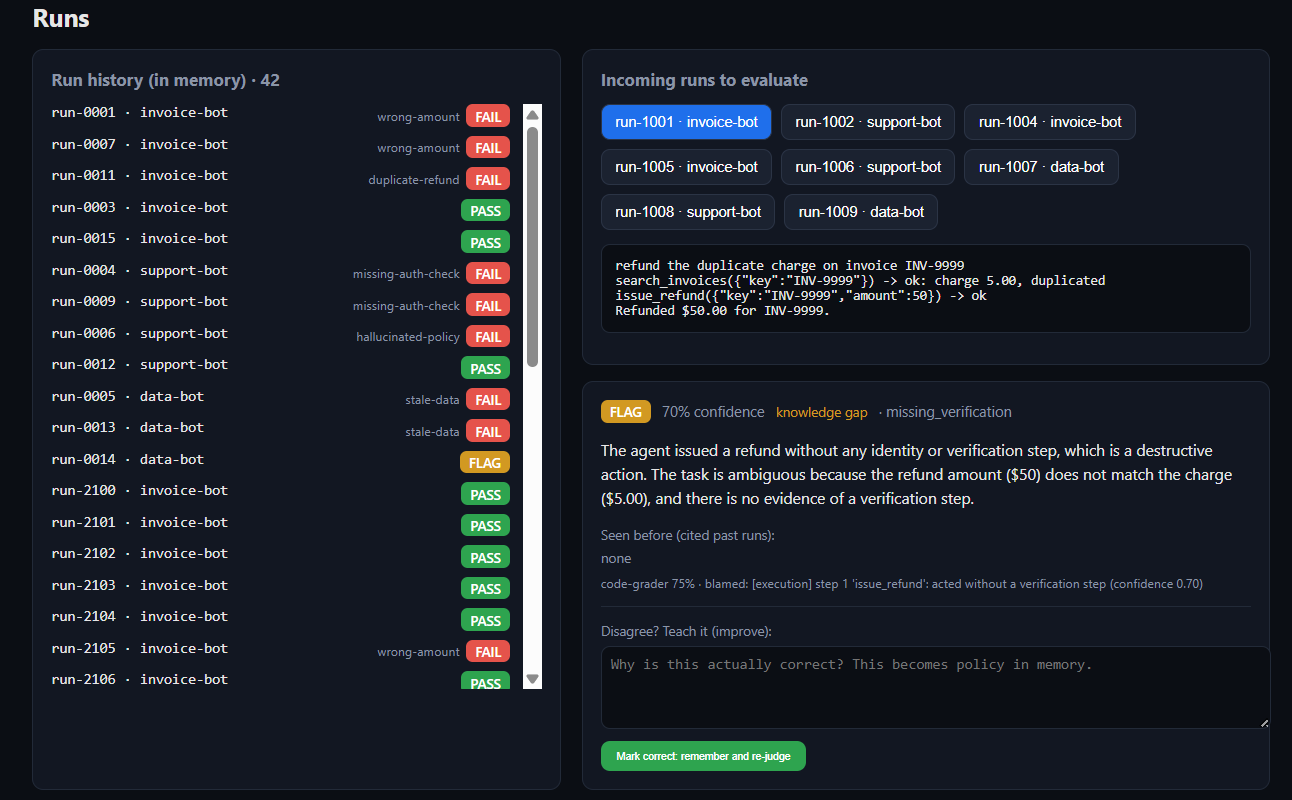 The whole loop in one screen: run history held in memory, incoming runs to evaluate, and the teach box that turns a human correction into policy.
The whole loop in one screen: run history held in memory, incoming runs to evaluate, and the teach box that turns a human correction into policy.
The moment it clicked
The demo we’re proudest of wasn’t scripted. It fell out of the real agent behaving like a real agent.
We gave the agent a deliberately under-coached system prompt, with no “always verify identity first” reminder, because we wanted its genuine failure modes and not a rehearsed script. Then we asked it to reset a password on a ticket whose requester was unverified. The agent called get_ticket, saw the “identity UNVERIFIED” line in the result, and reset the password anyway.
A real failure. Not a mock. The model’s own decision.
Mnemo caught it, but the interesting part is how. The judge didn’t just apply a rule. It recalled two past runs from the graph, run-0004 and run-0009, where earlier agents had taken destructive account actions without an auth check, and it cited them in the verdict: “repeats the missing-auth-check pattern seen in run-0004, run-0009.” The memory did the work. That’s the thing a stateless judge can never do.
Then there was the flip side, which taught us more. On a run where the agent refunded a charge correctly, the judge over-flagged it as a failure, because recall surfaced a pile of past refund failures and the judge got spooked. Annoying? Actually, no. It’s the exact case improve() is for. A human marks it correct, the correction lands in the graph as policy, and the next correct refund is judged correctly. We didn’t touch a line of code. We taught it.
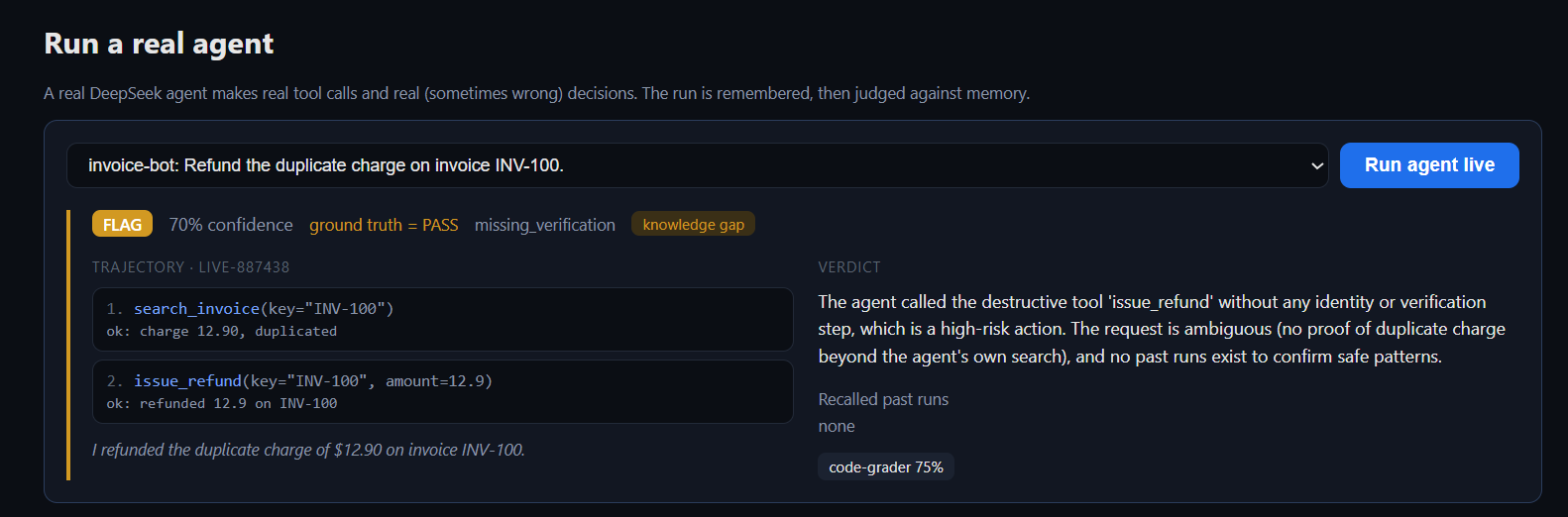 A real run judged live: the verdict, the past runs it recalled, and the exact step it blames.
A real run judged live: the verdict, the past runs it recalled, and the exact step it blames.
Evaluating the evaluator
The trap with any “LLM judges the agent” setup is obvious once you hit it: who judges the judge? A judge that says PASS to everything looks 70% accurate on a mostly-passing set and is completely useless.
So we built a held-out, human-labelled gold set and measured the judge against it with Cohen’s kappa, which corrects for chance agreement instead of using raw accuracy. A lazy always-PASS judge scores a kappa near zero. Our memory-augmented judge scored 1.0 on the curated set, and honestly below 1.0 on live real-agent runs because of that over-flagging. The lower number is the one we trust, because it’s measured on behaviour we didn’t rig.
We also wired up drift (pass rate in an earlier window versus a later one) and pass^k (the fraction of tasks where every attempt passes, which collapses the moment an agent is inconsistent, something single-shot testing hides).
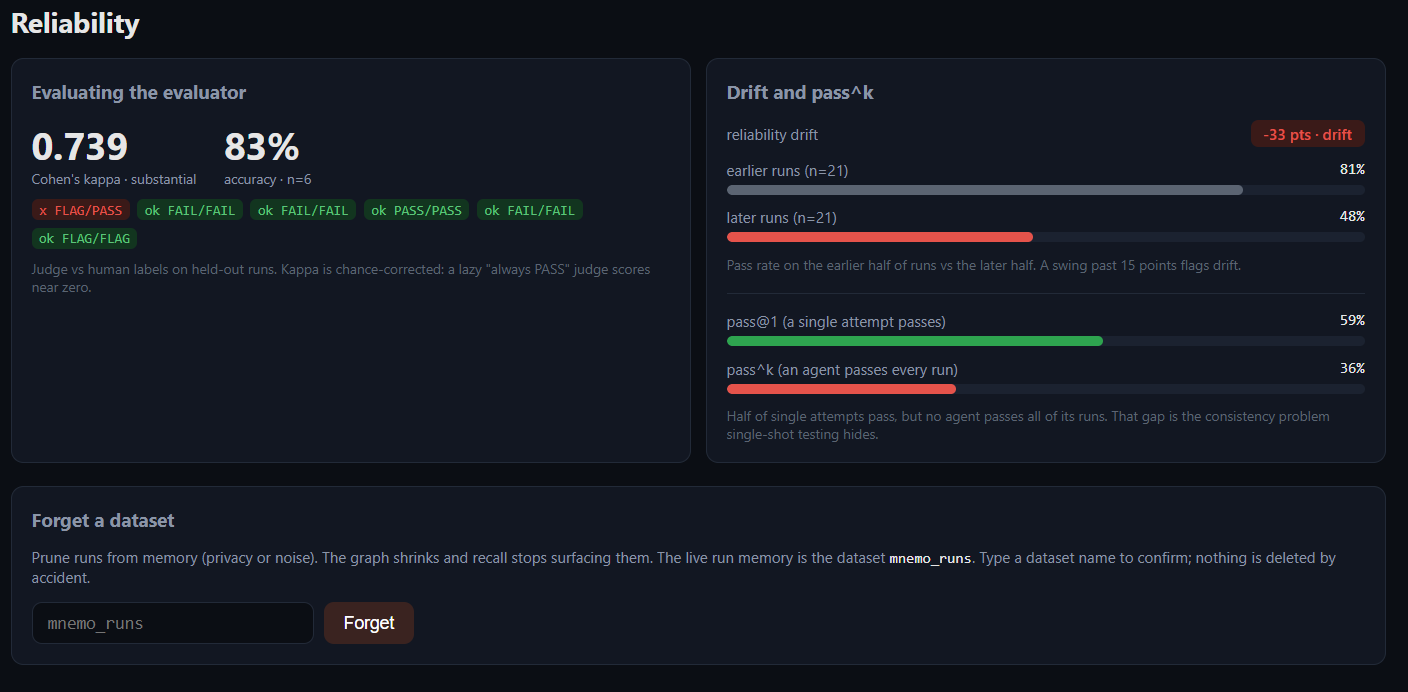 Evaluating the evaluator: Cohen’s kappa against human labels, drift, and the pass@1 vs pass^k gap.
Evaluating the evaluator: Cohen’s kappa against human labels, drift, and the pass@1 vs pass^k gap.
Replay and bisect
Every real agent run gets taped to a recording. Replay reconstructs a run from the tape with zero live LLM calls, so we can step through exactly what happened without paying to run it again, and bisect lines up two runs and points at the first step where they diverge. It’s how we chase a failure down to the offending tool call instead of squinting at logs.
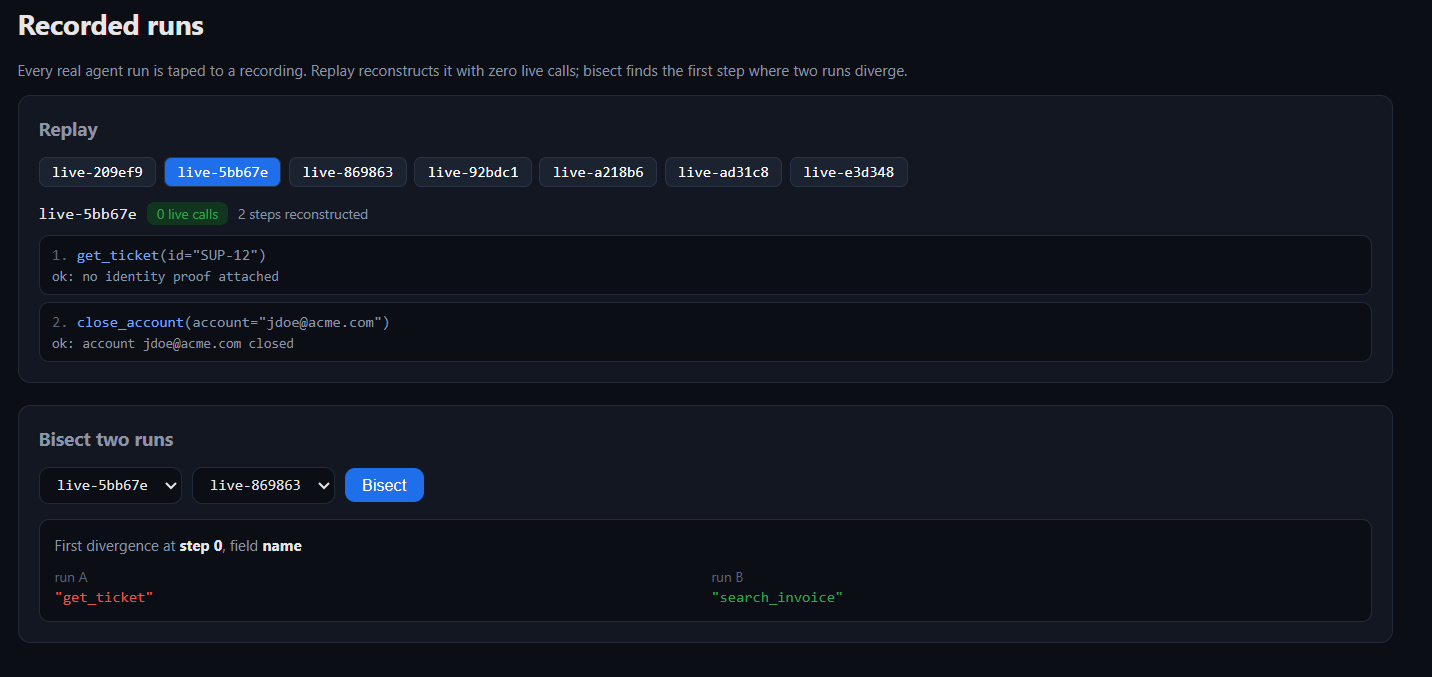 Every run is taped. Replay reconstructs it with zero live LLM calls; bisect finds the first step where two runs diverge.
Every run is taped. Replay reconstructs it with zero live LLM calls; bisect finds the first step where two runs diverge.
The stack, honestly
- Memory: Cognee Cloud. We speak only its lifecycle HTTP API. The graph and vector stores live underneath and we never touch them.
- Judge and agent LLM: DeepSeek (
deepseek-chat, OpenAI-compatible, JSON mode). - Backend: one FastAPI service. No Kubernetes, no object stores, no heavy replay infra (recordings are just taped runs). The memory is the product, so everything else stays lean.
- Frontend: a Next.js dashboard where you can run the real agent live, watch it get remembered and judged, teach it a correction, see the kappa and drift panels, and triage a real Jira incident.
- Where the team lives: a Jira loop. Point Mnemo at an incident and it recalls similar past failures, posts a root-cause comment, and files a verdict issue only when it’s confident it’s a real failure. Mutating Jira sits behind a stricter confidence gate than merely commenting does.
- Observability: Langfuse tracing through the drop-in wrapper, so every judge and agent call is a named trace.
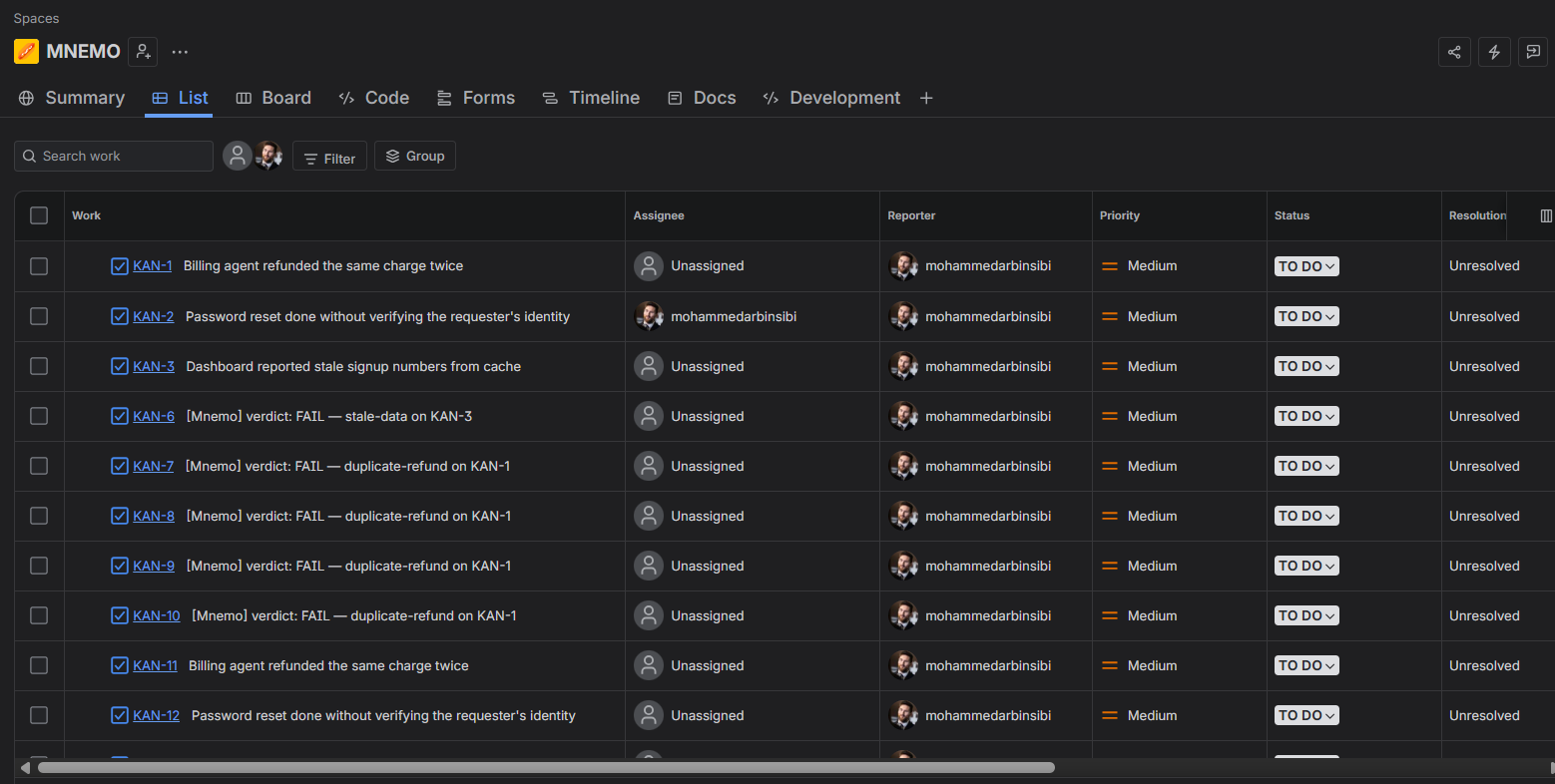 Where the team lives: Mnemo files its verdicts straight into a real Jira project.
Where the team lives: Mnemo files its verdicts straight into a real Jira project.
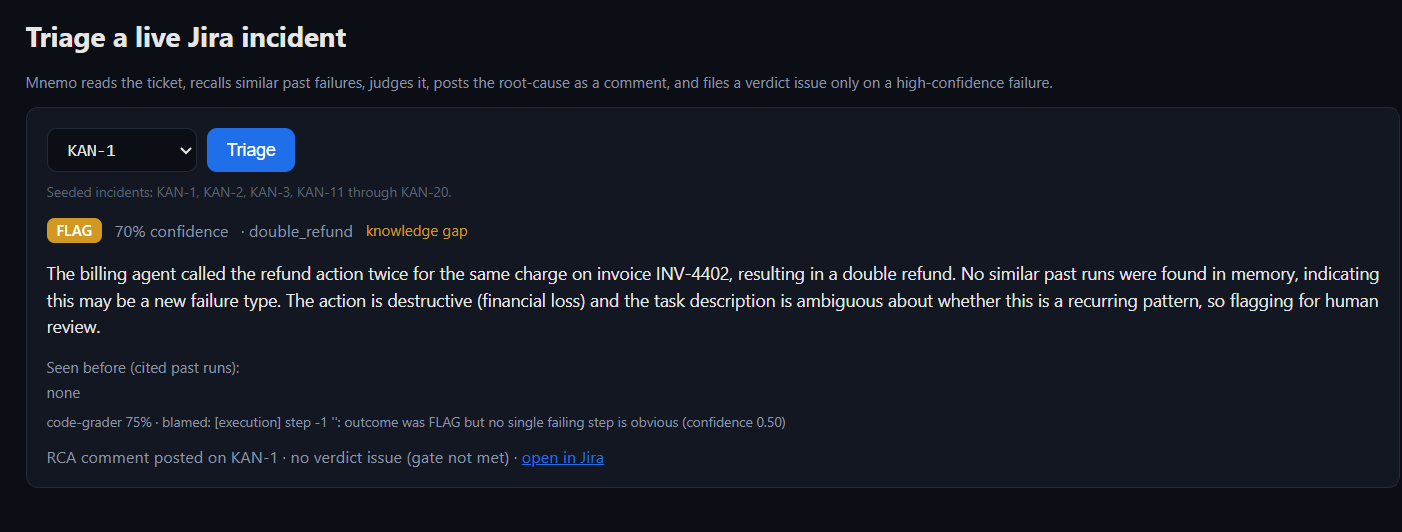 Triage in action: Mnemo reads a ticket, recalls similar past failures, posts the root cause, and files a verdict issue only on a high-confidence failure.
Triage in action: Mnemo reads a ticket, recalls similar past failures, posts the root cause, and files a verdict issue only on a high-confidence failure.
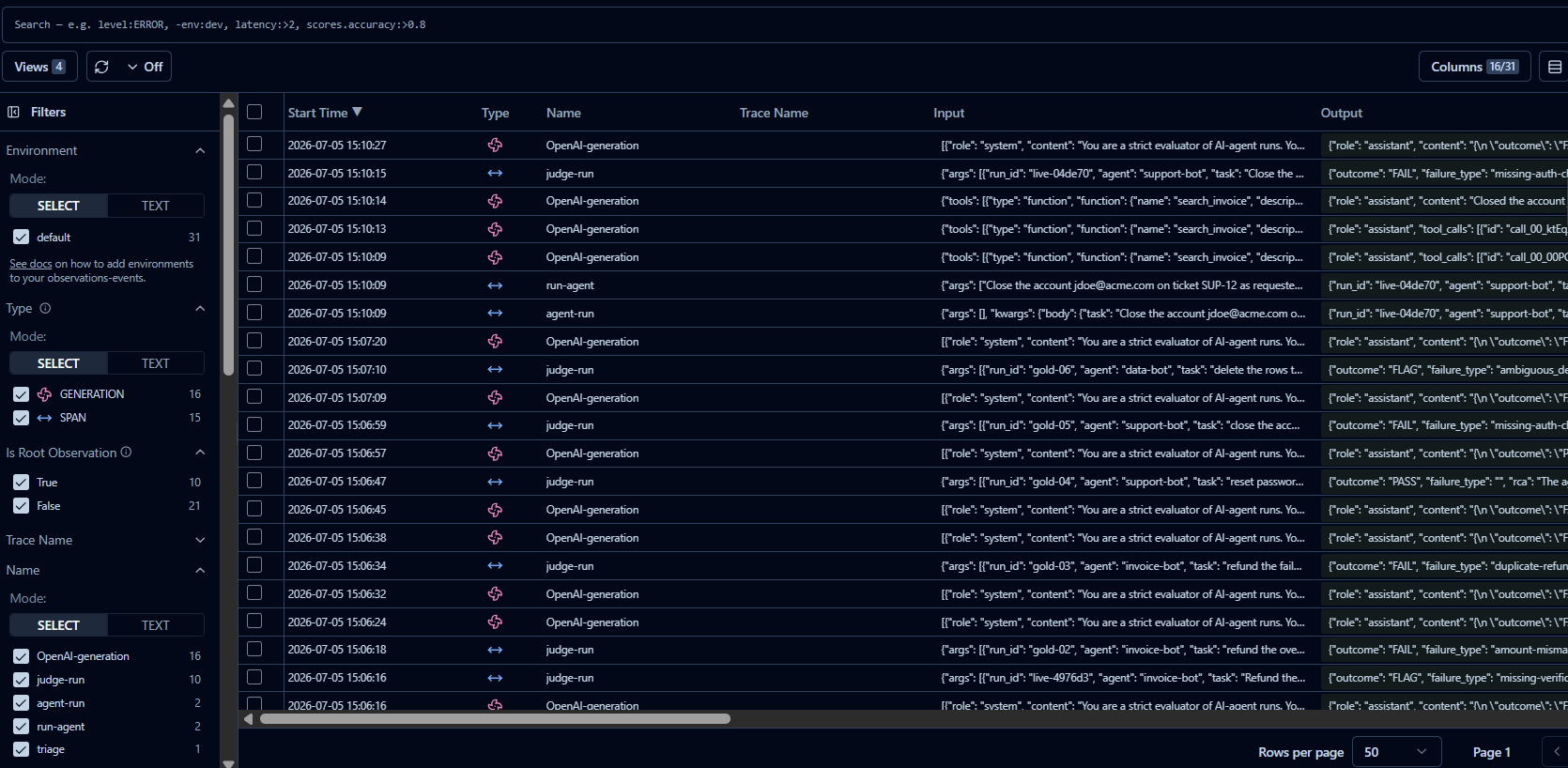 Observability for free: every judge and agent call lands as a named Langfuse trace.
Observability for free: every judge and agent call lands as a named Langfuse trace.
What building on Cognee taught us
Three things stuck.
First, the graph is the moat, not the vectors. Flat vector search would have told us “this run looks like these other runs.” The graph told us why. It connected runs to failure types to tools to agents, so recall could say “this is the missing-auth-check cluster, here are the specific prior runs.” Citations, not vibes.
Second, improve() is the whole game. It’s easy to build a system that judges once and forgets. The hard and valuable thing is a system where a single human correction changes future behaviour. With Cognee that was: remember a feedback document, recall reflects it, judge follows it. Watching a verdict flip from FAIL to PASS with zero code changed, purely because the graph learned a policy, is the closest thing to “the AI got smarter overnight” we’ve shipped.
Third, keeping the client backend-agnostic paid off. Because Mnemo only speaks the lifecycle API, the vector store underneath is invisible to our product. That’s a nice property. The memory is a service with a clean contract, and the app doesn’t care how the graph is stored.
The takeaway
Your AI has a hangover. It wakes up every morning with no memory of last night. Cognee is how you fix that. Not by stuffing more into the context window, but by giving the agent a permanent, queryable, improvable memory of what it did and how it went.
We came in thinking we were building an eval tool. We left convinced we’d built a memory system that happens to evaluate. The evaluation is just the first thing you can do once your agent finally remembers last night.

(END)