Have you ever searched a medical database for ‘lung cancer treatments’ only to get 500 blog posts about ‘clean eating’ because they both mentioned the word ‘lung’? That is the Lexical Gap
search technology is moving from keyword matching to understanding meaning. For many years, infrastructure used to rely on exact word matching, but now with the rise of AI infrastructure, the industry is moving towards understanding the hidden meaning behind a request. This guide talks about how search engines are changing from using keywords based to using neural networks and it introduces “Relevance Feedback” is a way to improve search results so they match what people are looking for without using the extra steps of traditional reranking
1. The Evolution of Search: From Keywords to Vectors
the journey of how we search for things is changing from “lexical” retrieval to a “neural” vector-based search. traditional systems look for specific strings, but neural search looks at the bigger picture
| Dimension | Traditional Keyword Search | Neural Vector Search |
|---|---|---|
| Mechanism | Lexical Retrieval (matching specific terms/strings). | Vector Retrieval (matching numerical representations of meaning). |
| Intent Capture | Low; relies on users knowing exact terminology. | High; captures context and semantic relationships. |
| Primary Limitation | Struggles with synonyms, polysemy, or phrasing variations. | Initial results can be noisy or prone to out-of-domain generalization issues. |
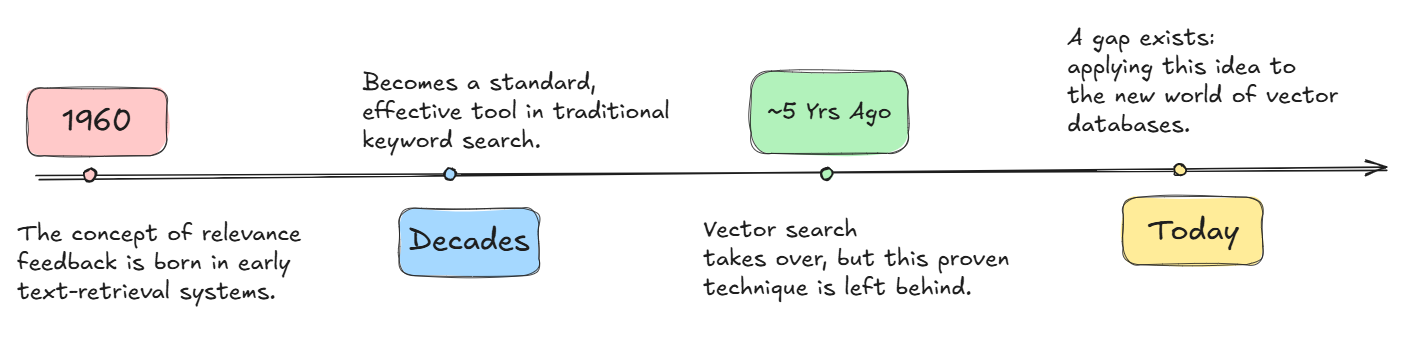
the ‘Relevance Feedback Gap’ illustrates how we lost this powerful tool during the initial rise of vector search, and why we are reclaiming it now
Understanding Embeddings: Data as Coordinates
to understand neural search, imagine a vast vector space, or a “forest.” In this forest, every piece of data (like text, images, or molecular structures) is represented not as a string of letters, but as a set of coordinates.
when we convert data into these coordinates using embedding models, we are mapping meaning into physical space. In this forest, similar ideas are located close to one another. A document discussing “cardiac arrest” and a query regarding “heart failure” will have coordinates that place them in the same grove, even if they share no overlapping vocabulary
however, because high-dimensional vector spaces are hard to understand and often contain billions of points, even the most sophisticated retrievers can struggle to find the exact clearing a user needs on the first try
2. Why Intent is Hard: The Problem with first retrieval
there is a documented “Gap” in information retrieval: users often have trouble precisely formulating a query, particularly when exploring unfamiliar topics. on the other hand, these same users are too good at judging how relevant a set of results is once they are shown with a list of options
this shift moves us from a one-shot retieval mindset to a Deep research loop, just like a human researcher explores a topic and pivots based on what they find. Relevance feedback here allows our system to iteratively refine its focus, bridging the gap between a vague initial query and the user’s actual intent
The Three Ingredients of Retrieval
every retrieval system has three main components:
- The Query: The first vector representing the user’s information need.
- The Documents: The huge collection of information stored in the vector index
- Similarity Scoring: this is the math function (like Cosine or Euclidean) used to measure the how close the query is to the documents
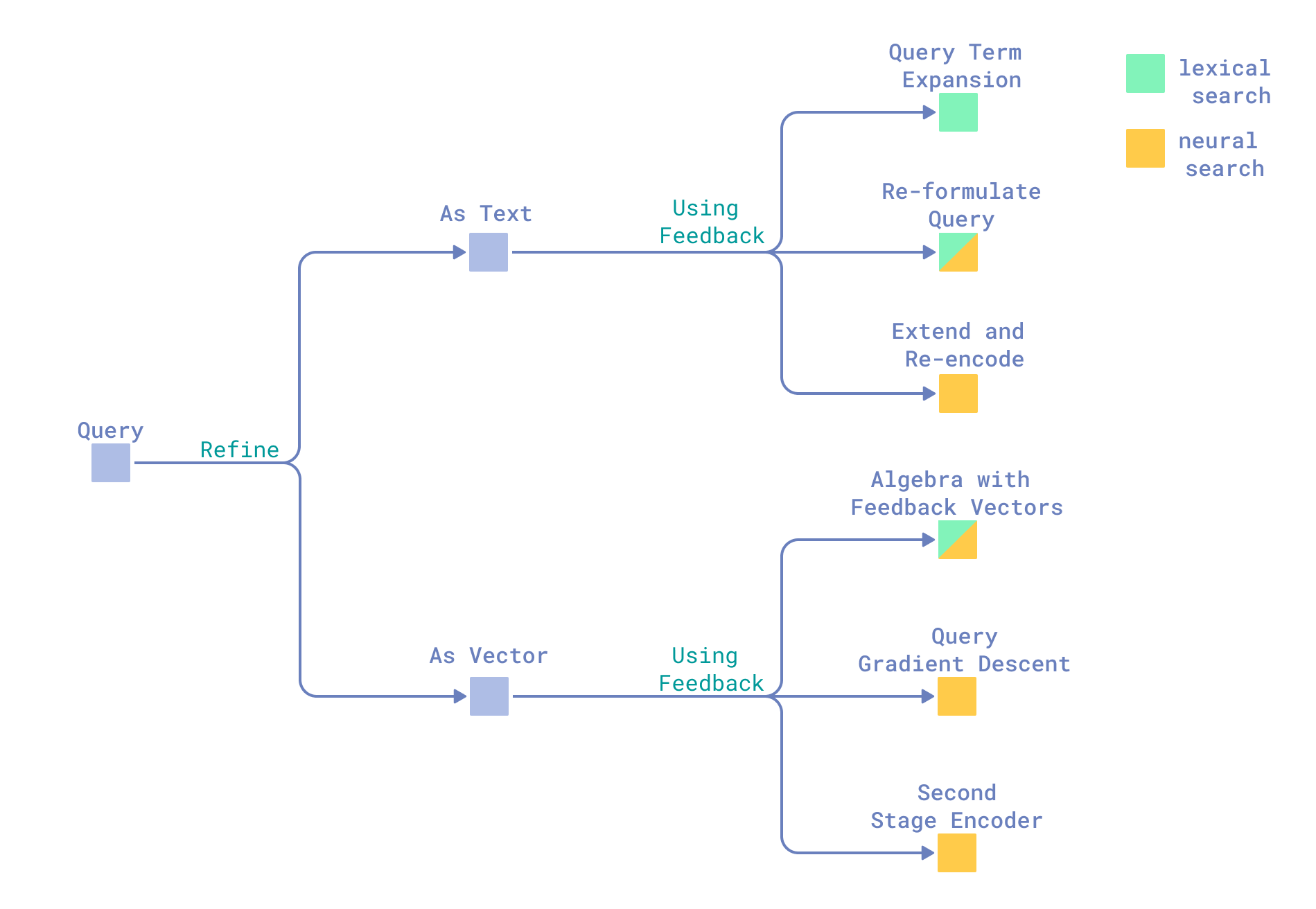
in production environments with billions of vectors, we can’t rebuild the index for every query/request. Traditionally, retrieval systems have been treated as “black boxes” that offer no built-in way to change scoring, forcing developers to rely on expensive external loops. To get around this, we need to work on improving the Query or the Similarity Scoring directly in the engine to bridge the gap between initial input and true intent
3. The Taxonomy of Relevance Feedback
Relevance Feedback is the process of simplifying signals from the first results to guide the next retrieval iteration
- Pseudo-Relevance Feedback (PRF): A “naive” approach that assumes the top N results are relevant. While it makes lexical search faster , it is prone to query drift in neural search, where the search results move away from the original intent
- Binary Relevance Feedback: This involves explicit user preferences (e.g., a “thumbs up”). While it is highly accurate, it is difficult to scale because users are reluctant and there is a risk that the initial results are so poor that there is no relevant signal to be captured.
- Re-scored Relevance Feedback: This uses automated “smart models” to provide detailed relevance scores. While accurate, the cost is too high. using a model like GPT-4o to re-rank thousands of documents for every query is not a scalable infrastructure strategy
in the past, these methods were not very good for production vector search because they were too slow, too expensive, and the strict context limit. To get around the high costs of fine-tuning while avoiding the problems of query drift, we use a native vector implementation
4. Qdrant’s Native Solution: The Relevance Feedback Query
Qdrant 1.17 introduces a native vector feedback mechanism that outperforms expensive re-ranking loops by moving the logic inside the engine itself (by integrating the feedback logic into the HNSW traversal process). This approach is designed for universality (working with text, audio, or molecular data) and efficiency
The Hiker and the Forest
we will refer to the same forest analogy used in the original qdrant blog :
- The Retriever Model (The Hiker): The initial model searching for the right path but doesnt have any local context.
- The Feedback Model (The Expert Friend): is more expressive model that looks at a small sample of “photos” (results) sent by the hiker and gives directional hints
- The Vector Space (the Forest): The total field of data where the search occurs
- A feedback model can be anything: a bi-encoder, a late interaction model, a cross-encoder, or an LLM
the “Expert Friend” doesn’t need to see the whole forest; they just provide guidance: “Move away from this swampy plant (negative signal) and toward that mossy tree (positive signal).”

by moving the feedback logic into Qdrant’s Rust-based core, we eliminate the “Tax of Reranking.” There is no longer a need to send large batches of data to an external model (like an LLM or a Cross-Encoder) for every query. Instead, the engine uses a native scoring formula to change the search direction in real-time, delivering accurate results in a single, low-latency pass
Technical Components of Feedback Scoring
Qdrant uses three main signals to adjust the movement through the vector space:
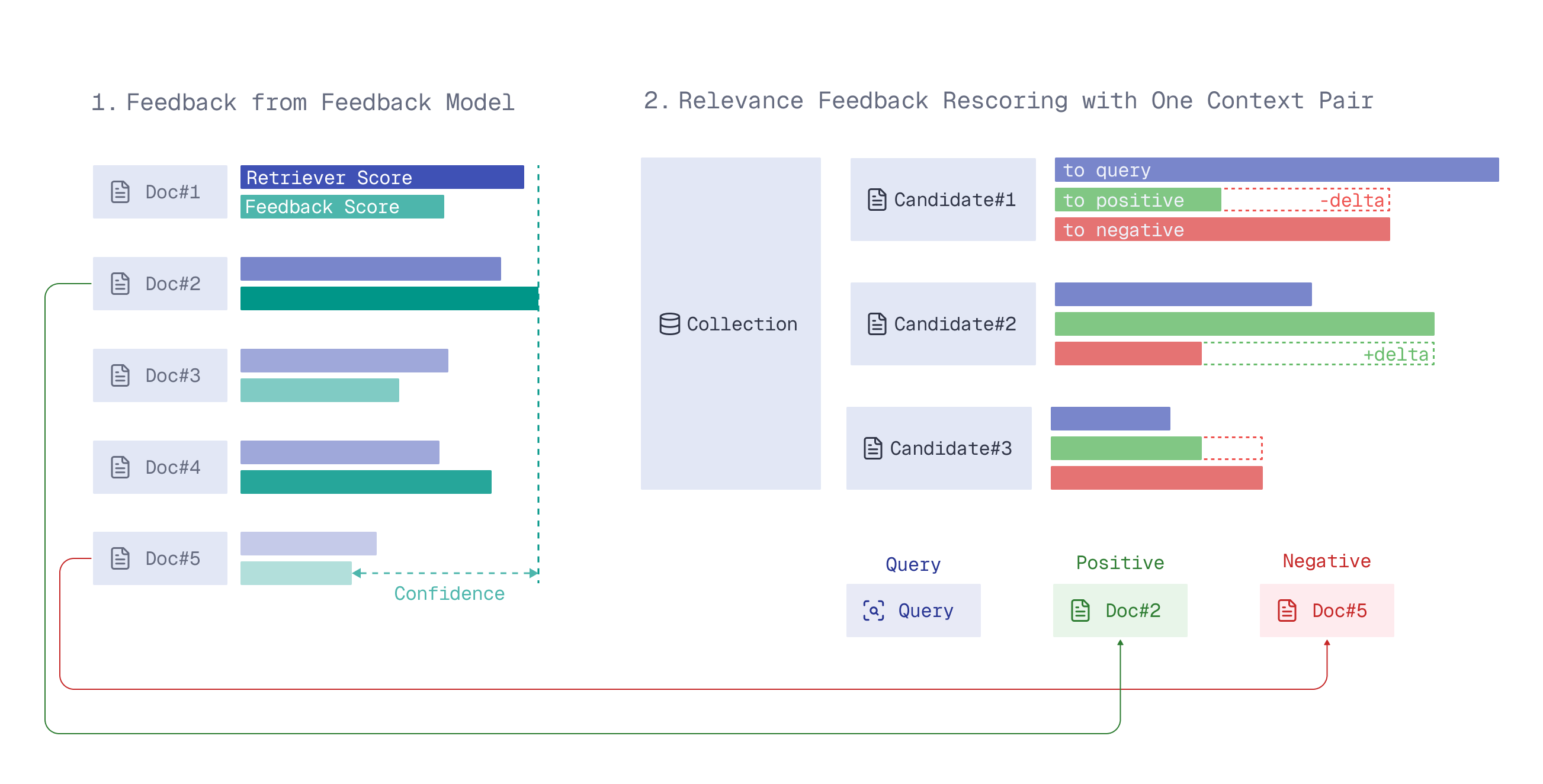
- Context Pairs: A relationship between a “positive” (relevant) and a “negative” (irrelevant) document
- Confidence: The difference in relevance scores between the two documents
- Delta: The change in direction the retriever needs to make to move closer to the positive example
the engine doesn’t just look for ‘closeness’ to the query; it calculates a “feedback-aware” score for every neighbor node it encounters during the search making it a truly index-native operation
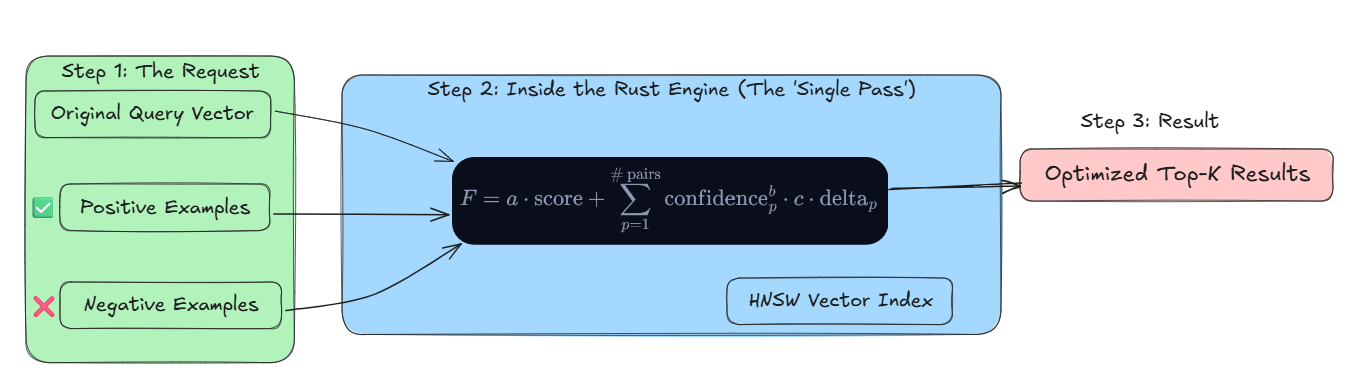
The Weighted Scoring Formula
to combine these signals, Qdrant utilizes a weighted formula that modifies how similarity is computed across the entire index:
In this equation, a, b, and c are variables adjusted to match the original query against the feedback. Crucially, it’s important to note that the exponent b makes sure that confidence and delta do not become one into a single joint term, which keeps the integrity of the directional signal. This allows the engine to traverse the vector space in a new, more relevant direction without needing to retrain the underlying models
5. Implementation: creating a Feedback-Aware Search
in a practical “Search Agent” use case, an agent can look at the first few results, identify which one is clinically relevant (positive) and which is a generic blog post (negative), and then use that “Expert Friend” logic to refine the search
Python Implementation
the following example show how to do this using a local cross-encoder for feedback, so you don’t have to pay the costs of LLM-based re-ranking
from qdrant_client import QdrantClient
from relevance_feedback import QdrantRetriever, FastembedFeedback
# 1. initialize the Retriever and the "Expert Friend" (Feedback Model)
# Using a local, CPU-optimized re-ranker for efficiency
retriever = QdrantRetriever(collection_name="clinical_research")
feedback_model = FastembedFeedback(model_name="BAAI/bge-reranker-base")
# 2. Train the formula weights (a, b, c)
# Warning: Use 50-300 real user queries. Training on sampled documents
# alone can cancel the feedback effect for specific use cases.
weights = retriever.train_parameters(train_queries, feedback_model)
# 3. Execute search using the learned weights
results = retriever.search(
query="Targeted immunotherapy for lung carcinoma",
weights=weights,
using_feedback=True
)
# for more code sample visit :https://qdrant.tech/articles/search-feedback-loop/“”Tip: to keep the latency low during big batch updates, use the prevent_unoptimized setting. This throttles updates to match the indexing rate of the Update Queue (which can track up to 1 million pending changes), this makes sure that queries only access fully indexed segments without losing the visibility of new data””
6. Measuring Success: Metrics that Matter
to understand how well Relevance Feedback works , we look at more than just how well people remember the information. we also look at how well it helps people find documents they didn’t know about
Abovethreshold@N: this is a measure of how many highly relevant documents, those exceeding the relevance threshold of the top-K results, are shown in the top N positions by the feedback formula- DCG Win Rate: a standard industry metric
(Discounted Cumulative Gain)it compares the ranking quality of the vanilla search against the feedback-augmented search
in the official Qdrant benchmark, this native approach has shown a DCG win rate of ~48% meaning that in nearly half of all searches the feedback aware provides a measurably better ranking than standard semantic search
the following table highlights the Relative Gain in Abovethreshold@10 across different datasets, which proves that the methodology works well
| Dataset | Relative Gain (Abovethreshold@10) |
|---|---|
| NFCorpus (Medical) | +21.57% |
| MSMARCO (General Search) | +23.23% |
| SCIDOCS (Scientific Papers) | +38.72% |
- more results and values you can find it here
what makes it super practical ?
- it is cheap: it only needs feedback from couple of documents not huge expensive batches
- universal : because it works on the mathematical structure of the data it doesn’t care if you re searching through text , images or even scientific molecules
- scalable : it can apply this knowledge to the entire database not just a tiny sample
the Relevance Feedback Query is a production-ready tool that goes beyond the “black box” limitation of traditional retrieval. Qdrant allows systems to move through all possible options with incredible accuracy and efficiency by including feedback directly into the scoring process
references
- Qdrant 1.17 - Relevance Feedback
- Relevance Feedback by Evgeniya Sukhodolskaya
- Relevance Feedback tuto
- Qdrant Documentation
- Qdrant Cloud Sign Up
- Subscribe to the Qdrant Newsletter

(END)